

So, you just got an incident notification or reliability alert. Now what? This page will help you respond to incident notification and reliability alerts. Stay calm. You got this. All you need to do is follow the process below. Take a deep breath and begin.
STEP ONE - Follow this checklist:
Determine the incident priority using this matrix:
Incident Classification
Incidents are classified by following the Major Incident Management Team’s matrix below and broken into 4 levels of severity:
-
Critical (P1)
-
High (P2)
-
Moderate (P3)
-
Low (P4)
VA Major Incident Management Team Matrix
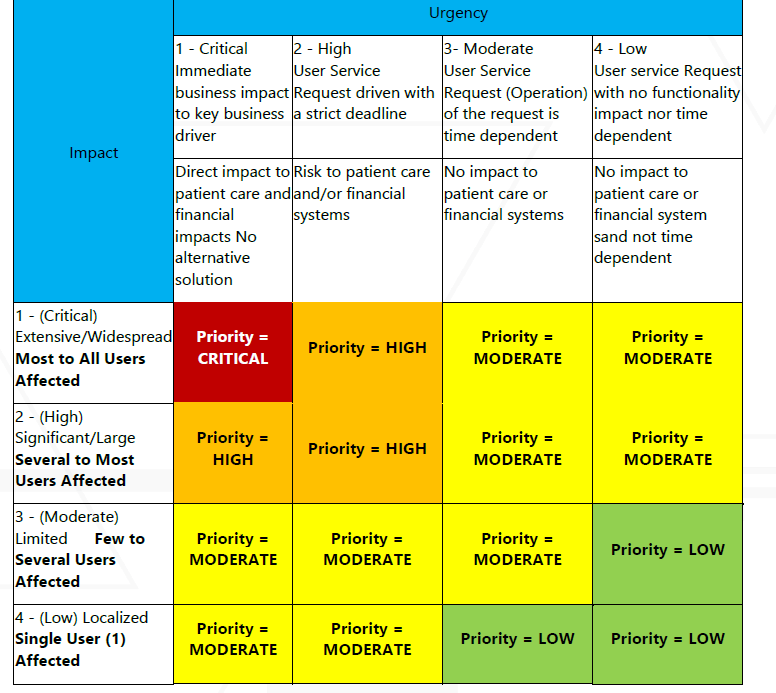
Impact can be defined as:
-
Extensive/Widespread > 10,000 Veterans affected per day OR a total product outage.
-
Significant/Large > 5,000 Veterans affected per day
-
Limited > 2,500 Veterans affected per day
-
Localized > 0 Veterans affected per day.
For incidents rated HIGH, MODERATE, and LOW:
Please reference the Resolution timeline below and then move onto STEP TWO.
For incidents rated CRITICAL:
FIRST: Determine whether the incident priority is correct. If the priority should be downgraded, adjust the incident priority level and document your reasoning on the incident.
Common reasons the priority might be downgraded:
-
The alert is a false positive
-
The number of affected users does not reach the P1 severity level
SECOND: Declare an incident in #vfs-platform-support if one has not already been created, and with the “Incident” label. Please follow the Incident Handling Steps in the VFS Incident Playbook for instructions.
This step will do the following:
-
Communicate to your team that the issue needs to be resolved ASAP.
-
Allow others who might reach out to notify you of an incident to see that you are already aware of it and actively working to resolve it.
-
Create a record that your team can use later - i.e., as part of a retrospective.
Don’t forget to:
-
Identify the Lead Engineer for resolving the incident (note – this is the person that will lead the investigation into the root cause of the issue) and ensure that person is listed as a responder of type SME on the Datadog incident.
Resolution timeline
Use this matrix as a guideline to prioritize your team’s time and actions:
|
Incident Priority |
Resolution Timeline |
Updates to reporter and VA Product Owner |
Temporary monitoring adjustments |
|---|---|---|---|
|
Critical (P1) |
ASAP - please dedicate any team member’s time who can fruitfully work on the issue, including off-hours |
Every 3 hours until resolved |
N/A |
|
High P2 |
Within the current week/sprint |
Every business day until resolved |
N/A |
|
Moderate/Low P3/P4 |
Within the next 2 sprints |
Upon resolution |
If the triggered monitor can be adjusted to ignore only the specific issue, do so and add an issue or acceptance criteria to restore the monitoring before the issue is considered resolved |
STEP TWO - Communicate
You must keep people informed. Below you’ll find a list of people you will need to contact.
Veterans
Use appropriate tooling and communication channels to ensure Veterans are aware of the issue as necessary and do not spend time doing work that will be lost. This may include:
-
Adding a downtime notification
-
Disabling a given app or feature
-
Direct communications such as emails, other alerting, etc.
Stakeholders
Ensure that your VA points of contact are informed and aware of the issue, its impact and expected resolution timeline. Please include a link to issues and/or slack conversations so that they may keep up to date on progress.
STEP THREE - Work the problem
Now it's time to deal with the problem. Follow the process below and you’ll be fine.
Determine the root cause
The incident commander should create a document to capture notes, discussions, and other items (screenshots, log messages, etc.) that can act as a part of the record of the incident for later reporting to stakeholders, and to assist the team when a retrospective is conducted.
Don’t forget to enlist help from Platform support and OCTO engineering points of contact.
Once you’ve determined a cause, proceed with resolution according to the general category of cause and communicate your finding clearly with the Platform Incident Commander for updates:
Resolve the issue
|
Cause category |
This might look like |
How to resolve |
|---|---|---|
|
External service bug/outage |
|
For P1 incidents: work with your OCTO point of contact to ensure that the Major Incident Management process has been triggered. In general, communicate with the service owners and work together to ensure that the root cause is addressed or has a plausible plan & timeline to be addressed. |
|
App bug or design issue |
|
Darn, can’t blame it on something else! Work to resolve the root cause. Ensure that all changes are tested with unit and end-to-end tests that will detect a re-occurrence. Be sure to consider whether UI changes are necessary or could aid in preventing the issue in the future. |
|
Internal service outage |
|
Create a support request with category “http://VA.gov incident” in #vfs-platform-support – trigger Pagerduty if necessary. |
|
Improperly configured monitor |
|
Sometimes an incident just ain’t an incident. Adjust the triggered monitor in a manner that will prevent re-notification for only this specific issue. Ensure that another engineer reviews the changes and confirms their specificity. |
|
Cosmic rays / Karmic justice / other incidents without clear causes or resolution |
|
Ensure that any affected Veterans are made whole. This might include manual re-submission of applications or reaching out via approved communications channels to explain the incident and how they can re-start the task they were trying to complete. |
STEP FOUR - Wrap things up
Good job. Now it is time for the post-mortem. To wrap things up, please follow the process below.
Postmortems:
Ensure that a formal post-mortem is created and shared with all relevant stakeholders.
For Everyone:
Ensure that your team’s VA points of contact are aware of the incident resolution and given a chance to review the post-mortem as well as the VA Platform’s points of contact (Steve Albers and Erika Washburn)
CONGRATULATIONS
You have successfully handled an incident notification or reliability alert. Thank you for following the steps in this document. You can relax now.
Help and feedback
-
Get help from the Platform Support Team in Slack.
-
Submit a feature idea to the Platform.